
Modularity and assembly: AI safety via thinking smaller
Applying systems thinking and disaster theory to AI safety

In 1984, Charles Perrow wrote the book Normal Accidents: Living with High-Risk Technologies. The book is an examination of the causes of accidents and disasters in highly complex, technological systems. In our modern time it can be helpful to review the lessons that Perrow set forth, as there may be no technology with more potential risks than AI.
I’m going to review some of the concepts that Perrow covered in this book, and in his other book The Next Catastrophe. I’ll explore how they might be used to construct safer AI systems, less prone to loss of control or pursuing undesired objectives, as well as misuse. I’ll also argue that making smaller, specialized AI modules might be preferable to making large, general models.
The fundamental idea of Normal Accidents is that while we typically think of accidents and disasters as deviations from a working process or system, the truth is that accidents are normal in any sufficiently long running system. Those who work on system safety must acknowledge that it’s only a matter of when, not if, a system has an accident. They must design the system accordingly.
Complexity
There are a variety of variables we can examine to determine how likely an accident is to occur at any given point in time, and how devastating the outcome of the accident is likely to be.
According to Perrow, one of the major attributes that contributes to accidents in a sociotechnical system is complexity. Complexity is a measure of how interconnected various components of a system are. These can be technical components, biological components, chemical, physical, etc.
You can organize systems by their complexity, by the flexibility of the processes involved in the systems. Complex systems are those defined by highly interconnected components. They typically provide limited, indirect, and ambiguous data about their operation to those who oversee and operate the system. An employee/operator within a complex technical system may be trained to focus on a single component, knowing very little about the rest of the system.
Complex systems are the opposite of linear systems. Linear interactions are easy to follow, see, and predict. In these situations, it’s easy to see which system components are doing what. Cause and effect in the system is straightforward, with alterations to one component causing repeatable, expected changes in downstream components.

Problems in complex systems are difficult to solve, and it’s hard to restore a complex system to working order if something goes wrong. This is often because fixing a problem in complex systems rquires in-depth knowledge of system components, which is rare. If the average person cannot intervene and help correct a system due to its complexity, that increases the risk in the system.
In “The Next Catastrophe”, Perrow’s later book, he discusses the importance of understanding complex systems and safeguarding society from disasters by using structural changes. These structural changes include reducing the concentration of assets, populations, and resources in ways that avoid creating centralized points of failure. One method of distribution is Just In Time Assembly (JITA).
Just in Time Assembly (or Just In Time Operation) is the practice of assembling and using system components right as they are required. JITA in complex systems minimizes inventory costs, reduces storage requirements, and identifies quality issues quickly by assembling components only when they’re needed. JITA also has an important role to play in safety.
JITA is valuable for safety in complex systems because it helps manage and reduce emergent behaviors and unexpected interactions. By minimizing the time components spend interacting, it reduces the opportunity for unforeseen interactions or failure cascades that can arise from the system's inherent complexity.
For example, in nuclear fuel fabrication, keeping minimal inventories of fissile materials through JIT processes reduces criticality risks. By only bringing together the necessary quantities of enriched uranium when needed for fuel rod assembly, facilities minimize the possibility of accidental critical mass formation or other unexpected nuclear reactions.
Additionally, in complex systems where component behavior might change over time (like biological materials, sensitive electronics, or reactive chemicals), JITA ensures that parts are used in their optimal state rather than potentially degrading in storage. This is especially important when system behavior depends on precise component properties.
JITA in AI
The AI safety version of JITA for advanced AIs might include strategies like: frequently resetting model weights in the network, resetting model contexts, restricting model operating contexts, and swapping out modular model components.
The strategy of resetting or limiting the model context already seems to work in certain instances. When Bing’s AI chatbot first launched, it rapidly became the subject of scrutiny as it displayed a variety of unhinged behavior like gaslighting and threatening users. One of the strategies Microsoft used to stop this undesired behavior was limiting the length of the conversations, occasionally forcing users to start a new chat and hence changing the model context. Microsoft limited users to 50 chat turns a day and 5 chat turns a session. It seems that very long chat sessions ended up “confusing” the model, which made the inappropriate behavior more likely.
In addition to occasionally resetting the model context, you might think about resetting the model weights themselves, occasionally retraining parts of the model before redeployment.
This may help limit scheming and strategic execution of unaligned goals from a sufficiently advanced model. If you’re worried about the possibility that a powerful model may pursue its own goals, you could attempt to address this by limiting how long that model exists.
Essentially, you would only let the model do a certain amount of work on a problem, then reset the weights and retrain the model. You then give the partially completed project and the context to the new version of the model, and let it continue to work.
This is analogous to how research programs for secret, sensitive work are handled – labs and agencies may use compartmentalization to limit an individual researcher’s knowledge of the full scope of a project.
A CIA analyst or operative may have access to only the information needed for a specific task, kept in the dark about the broader implications of the project they’re involved with.
Occasionally resetting model weights may also help prevent powerful models from achieving goals by taking advantage of the time-delays inherent to formulating, executing, and achieving a multi-step plan.
Consider a situation like a corporate office worker trying to convince another firm to sell them certain assets. The initial offer must be sent, then the receiving representative must discuss the documents with his supervisor if necessary, and potentially send back a counter-offer. This pattern may also hold true for an advanced AI trying to bribe a human with Bitcoin. In multi-agent systems there’s time delays, during which information and action need to propagate.
There are delays between when an agent first decides on a goal, formulate a plan, takes an initial step to achieve that goal, gathers feedback about the consequences of the attempt, then takes another step, etc. If you assume that there’s always going to be delays in a process like this, then you can take advantage of these delays by occasionally resetting the model. It doesn't matter if you're the best schemer in the world if you can't reliably take the next steps to act on your plan.
Obviously one of the big problems with this strategy is that you have to frequently retrain a model. This imposes substantial training costs onto this scheme. But you might be able to get away with retraining just certain sections of the model. This is why producing modular models where components can be swapped in and out may make more sense.
Modularity
You can make systems less complex and more robust to failure by making them modular, able to swap components in and out without failure, even if there’s some amount of data loss.
For digital information systems, this typically looks like making certain functionalities modular, such as certain chunks of code, or packages of certain resources.
Digital software modularity may include versions of JITA, such as applying certain powerful but necessary modules to the system at run-time, then decompiling the system after the desired tasks completed.
Neural networks consist of layers of interconnected neurons. If one could decompose these layers and turn them into modular components, this would enable you to assemble parts of a network according to your needs and goals. You could then disassemble the network after use, instead of allowing an entire model to run in one environment for extended periods.
Imagine having different “heads” of a model, specialized for different tasks, that you swap around according to your goal at any one time. This might even improve the flexibility and overall utility of an AI system environment.
Right now there are actually some modular components that you can apply to an AI model to alter the behavior of the model. Low-Rank Adaptation (LoRA) refers to the process of optimizing a small set of parameters, swapping out optimizations as needed. This allows for quick adjustments to pre-trained models without the need for full retraining.
Research is also being conducted on techniques for fine-tuning models at inference time, which would theoretically let you optimize a model for your needs and then revert the model back to its base state afterwards.
Sakana AI recently published some research on what they call Transformer^2 (Transformer squared), which is essentially doing just-in-time fine-tuning during inference. Instead of permanently modifying the model's weights like traditional fine-tuning, the strategy involves keeping a small set of pre-trained "expert vectors” for different capabilities (math, coding, etc.). Then when a query comes in, the model determines what kind of task it is and adjusts model behavior by applying the right combination of expert vectors. After a response is generated, you can return the model to its base state.
One may just need to scale up these methods of adaptation and inference-time fine-tuning to be able to effectively compose most of a model at run-time, use the model for only a limited amount of time, then tear-down the model afterwards.
Another advantage of modular components is that it makes it easier to decouple systems.
System coupling
System coupling is another concept discussed by Perrow. It’s one of the attributes that impact the likelihood and severity of an accident (at any given moment) within a sociotechnical system.
Coupling describes the amount of influence one component of a system has on another system component. Tight coupling often occurs in processes like chemical reactions. In chemical reactions, changes in one chemical component immediately and significantly affect other parameters, often with nonlinear relationships. For example, temperature changes alter reaction rates exponentially, affecting pressure, concentration gradients, and heat transfer simultaneously.
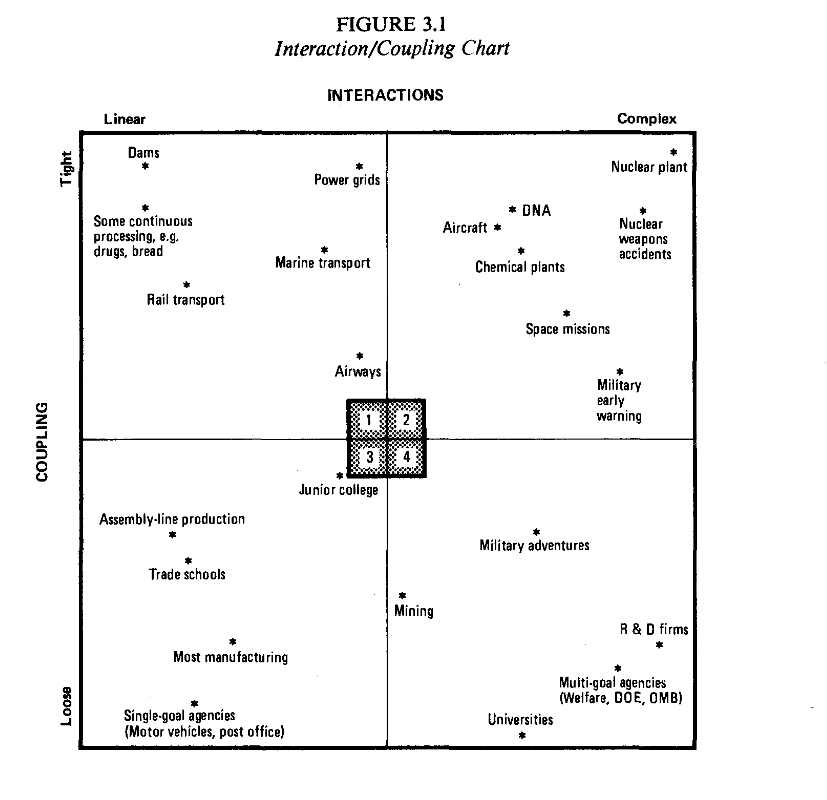
These tightly coupled systems must be buffered with safety components like automatic shutoffs, safety alarms, and redundancies. These are necessary because in tightly coupled systems humans may have limited ability to interfere in processes, and improvising during an accident involving these processes can be quite difficult. Interventions may need to be done in a specific order or it may be hard to substitute personnel or technical components.
One of the defining characteristics of tightly coupled systems is that they don’t allow for delay. Additionally, failures of single components may have cascading, knock-on effects that trigger failure in other system components downstream. In highly coupled systems it’s often the case that components rely heavily on expected, continous outputs from other system components. Small changes in one component may cause a downstream component to misfire, which can cause the next link in the chain to misfire, etc.
By contrast, loosely coupled systems are better able to tolerate delays. These systems are flexible, with more opportunities for operators to intervene and recover if something goes wrong.
In fact, there are necessarily time delays outside of small isolated testing environments. Any system that relies on interactions with other people or with other computer systems is necessarily subject to time delays. Once again, you could take advantage of these time delays to potentially catch or interrupt scheming by a model.
Making AI systems more modular and decreasing coupling means you could potentially inject time-delays and checkpoints into AI model architecture and activity, using these gaps to check for signs that something is wrong.
Taking a tightly coupled system and finding a way to make it more loosely coupled enables you to create systems with more redundancy, able to resist single points of failures and knock-on effects, giving system operators more opportunities to intervene.
JITA techniques could potentially allow AI systems to assemble or modify components on-the-fly. You could make use of an architect-ing framework that routes queries and tasks to the correct modular components, activating these components when necessary, then deactivating them afterwards.
The current model development paradigm is to train highly general, powerful systems. More general systems are more dangerous as they necessarily include a lot of knowledge and capabilities that can be misused, misapplied, or misfire.
Modularity and decoupling may mean you don't have to develop systems that are extremely generally competent, focusing instead on developing certain domain capabilities as modules you can plug in to less generally capable systems as needed. You make less capable models as the model base and then assemble their capacities as needed for the domain you’re working in.
Research
There’s already ongoing research into ways to create AI model architectures that are more modular and able to be assembled on the fly. An international team of researchers have collaborated on a system they dub Model Disassembling and Assembling (MDA), which tries to breakdown an AI model into subsystems that can be compiled and torn-down with a “LEGO-like” flexibility.
The authors of the paper propose a method of breaking down models into components that are “task-aware”, then assembling these components into models that are optimal for a specific task. The researchers extracted certain parts of the model into “single-task components”. Various strategies were used to scale parameters and address potential differences in magnitude between the parameters of different model components.1
They found that single-task components typically matched or even exceeded the performance of the original model, for a given task. When multiple components were compiled together, performance remained generally good, although there was some chance of performance degradation when many components were compiled together.
This shows you can potentially extract specific parts of an entire network, like just the output layer.
In terms of transformers, you could potentially train a shared transformer backbone that learns all of the rich text representations. You would then have multiple heads, for things like specific style generation or different constraints, that you would swap in based on your chosen criteria.

Theoretically this would maintain most of the value in a general model, but limit the ability of a powerful model to do long-term planning and execution since its “head” is swapped out frequently. The output components would also be much smaller than the full model, making them easier to swap and fine-tune as needed.
There are some limitations we would probably need to overcome to make this a viable model training paradigm. Dependencies between parameters could make clean separation difficult, so you’d have to find a way to deal with that. Furthermore, any compression/decompression would need to preserve numerical precision. Reconstruction at runtime would need to be extremely fast and reliable.
You might be able to address some of these issues by factorizing weight matrices (like SVD decomposition). Layer-wise decomposition might be possible since transformers have natural layer boundaries. You could potentially identify clusters of highly-related weights, potentially separable components, using techniques similar to model pruning.
To be sure, there probably are costs you would pay for this kind of training scheme. The model outputs may suffer degradation, with noise resulting from components that don’t perfectly interact with one another. Though the price might be worth paying when working with sufficiently advanced, dangerous models.
Richard Ngo hypothesized that a modular approach combined with pruning “raises a counterintuitive possibility: that it may be beneficial to train agents to misbehave in limited ways, so that they develop specific modules responsible for those types of misbehaviour, which we can then remove.”
This seems like it might actually bear out as a possibility, given that recent research has found that you can train a modular network to learn specific concepts, then alter those modules into more fine-grained, lower-level concepts. A German research team created specific modules intended to detect traffic signs. They found that confusing a yield sign with other triangular signs was safety-critical, so they specifically improved on a module that detected triangles by splitting the triangle concept into "upward-pointing" and "downward-pointing".
An approach like this could make it easier to verify system safety. Right now, red-teamers have to try and ensure safety for an entire AI model at once. They write prompts intended to try and jailbreak systems, gaining access to a lot of capabilities if they are able to do so.
Modularity could enhance system safety by making testing easier. Instead of trying to verify safety for the entire system at once, you could define specific safety requirements for each module and then test and validate modules independently. You could also apply more stringent requirements on safety-critical concepts.
A team of researchers at Microsoft recently experimented with extending the utility of modular model development by devising strategies for optimizing the training of expert models and coordinating individual expert modules to handle different tasks. They created a taxonomy to compare different methods of modularization, which includes both strategies to route tasks to specific expert models and the application of models to specific domains.
Microsoft’s researchers note that one benefit of this style of training is that it may:
“Drive model transparency and accountability. Modular models allow specific expert models to be identified and, if necessary, removed or retrained. For example, if a module trained on PII, copyrighted, or biased data is identified, it can be removed more easily, eliminating the need for retraining and helping ensure compliance with privacy and ethical standards.”
Essentially, modular systems may be easier to interpret and understand, as the function of each component can be analyzed separately. This could help in identifying and mitigating potential safety risks, if you could extend the analysis to isolating and removing dangerous capabilities from a model. Individual modules could also be rigorously tested and validated before integration, leading to more robust and safer AI systems.
Modular development and task-routing may actually be an easier, more efficient way to train models, assuming the routing problem can be figured out.
To summarize, this modular approach would provide concrete advantages over traditional monolithic approaches:
Problems could be isolated to specific modules
Improvements could be targeted where needed most
Testing and validation could be done at a more granular level
Safety requirements could be tailored to the importance of each concept
Highly flexible and general systems don’t need to be created
Others have argued that the black-box problem of neural network architecture can be addressed by finding strategies to decouple and modularize both data and memory.
Combining a modular design scheme with JITA techniques could enable safer use of powerful AI systems by training in advanced capabilities (in certain domains) to specific modules, assembling these modules just in time for use as queries are routed to them, then removing or resetting the modules afterwards.
The techniques described above may help human operators maintain control over the AI system and its environment while still getting utility from powerful, advanced AIs.
…But I want to note here that this still doesn’t solve the alignment problem. Ideally, you would use some combination of both alignment techniques to ensure any powerful module has a sense of ethics and human well-being, even if that module is used only for specific tasks. It would be akin to having a team of 100 highly ethical domain experts, each expert sometimes called upon for their knowledge regarding certain tasks.
As AI capabilities continue to advance, we’ll need to start thinking about how to limit capabilities to just the contexts in which we want them used, limiting their potential for misuse. JITA and modularity can be a part of that answer.
In this context, this meant that for the problem of classifying items in the CIFAR-10 dataset, category "0" is one task, category "1" is another task. They extracted just the parts of the network most relevant for classifying specific categories into specific modules.